
5 Proven LSTM Architectures for Incomplete Time Series Forecasting
Discover five powerful LSTM (Long Short-Term Memory) architectures tailored for incomplete time series forecasting. Learn how each model handles missing data and improves accuracy in real-world scenarios.
What is LSTM for Incomplete Time Series Forecasting? Understanding the Foundation
LSTM (Long Short-Term Memory) is a specialized recurrent neural network (RNN) architecture designed to model sequences and capture long-term dependencies in data. Unlike traditional RNNs that struggle with vanishing gradients, LSTM for incomplete time series forecasting uses a sophisticated gating mechanism to selectively remember and forget information over extended sequences.
These networks have become the backbone of time series forecasting, particularly excelling in scenarios where data exhibits complex temporal patterns or contains noise and missing values.
The Challenge: Why Standard LSTM for Incomplete Time Series Forecasting Falls Short
Standard LSTM architectures operate under the assumption of regular time intervals and complete data sequences. However, real-world time series data rarely meets these ideal conditions. Missing values are commonplace due to:
- Sensor malfunctions in IoT deployments
- Human error in data collection
- Network transmission failures
- Equipment downtime during maintenance
When faced with incomplete data, traditional LSTMs experience significant performance degradation, making specialized approaches essential for maintaining forecast accuracy.
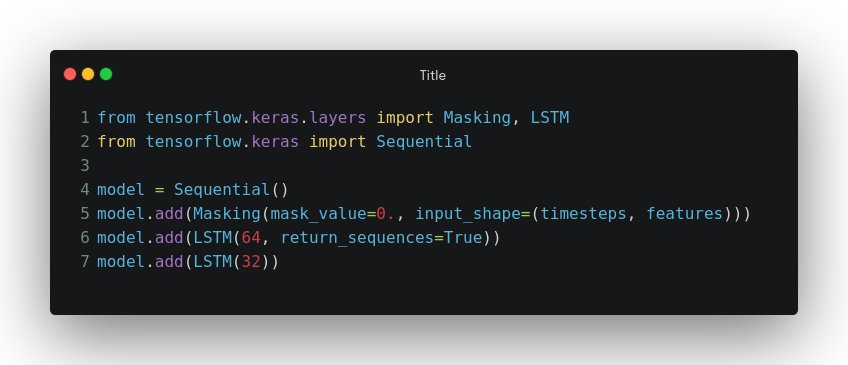
Architecture 1: Masked LSTM for Incomplete Time Series – Focusing on Known Values
The Approach
Masked LSTM employs masking layers that instruct the model to ignore missing values during both training and inference phases. This approach allows the network to focus exclusively on available data points without being confused by gaps.
Implementation Strategy
Key Advantages
- Selective attention to valid data points
- Reduced noise from interpolated or imputed values
- Straightforward implementation with minimal preprocessing
Real-World Application
Industrial IoT systems benefit significantly from Masked LSTM when dealing with sensor networks that experience occasional dropouts. Manufacturing plants using this approach report more reliable equipment failure predictions despite intermittent sensor data.
Architecture 2: Bidirectional LSTM for Incomplete Time Series – Leveraging Past and Future Context
The Approach
Bidirectional LSTMs process sequences in both forward and backward directions, creating a comprehensive understanding of temporal context. This dual-direction processing proves invaluable when missing data occurs in the middle of sequences.
Implementation Example

Performance Impact
Healthcare forecasting applications using Bidirectional LSTM demonstrate up to 8% improvement over unidirectional approaches, particularly in patient monitoring systems with irregular data collection intervals.
Optimal Use Cases
- Medical monitoring with sporadic measurements
- Financial markets during trading halts
- Environmental sensing with weather-dependent gaps
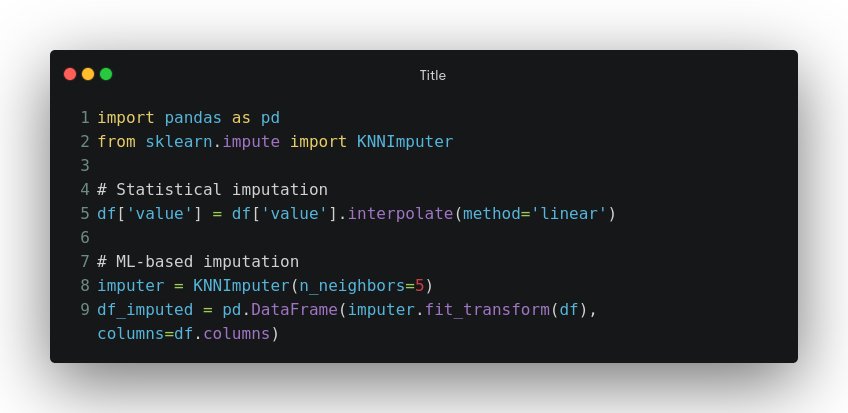
Architecture 3: LSTM with Imputed Data for Incomplete Time Series – Preprocessing for Completeness
The Approach
This strategy involves preprocessing missing values using statistical or machine learning-based imputation techniques before feeding data to the LSTM. By creating complete sequences, the model can leverage its full temporal modeling capabilities.
Implementation Techniques
Strategic Advantages
- Maintains temporal continuity in sequences
- Preserves LSTM architecture without modifications
- Flexible imputation methods for different data types
Financial Market Success
Investment firms applying this approach to handle missing trade data report 6% accuracy improvements in price prediction models, particularly during market holidays and technical outages.
Architecture 4: Attention-based LSTM for Incomplete Time Series – Smart Focus Mechanism
The Approach
LSTM Autoencoders combine reconstruction and forecasting in a unified framework. The encoder compresses the input sequence (including gaps) into a latent representation, while the decoder reconstructs the complete sequence before making forward predictions.
Architecture Implementation
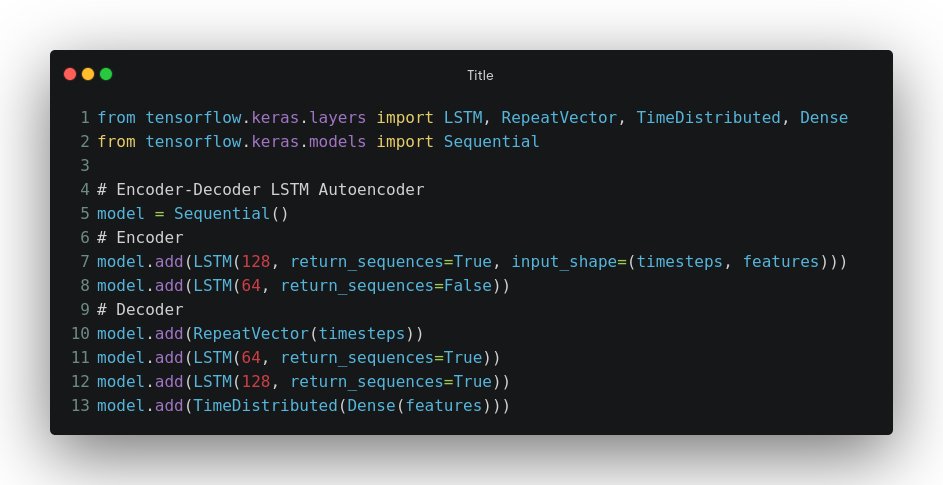
Dual-Purpose Benefits
- Learns data patterns and gap characteristics simultaneously
- Robust reconstruction of missing sequences
- Enhanced forecasting through better sequence understanding
Climate Research Applications
Meteorological institutions use LSTM Autoencoders to handle large gaps in weather station data, achieving 7% improvement in long-term climate predictions despite significant missing data periods.
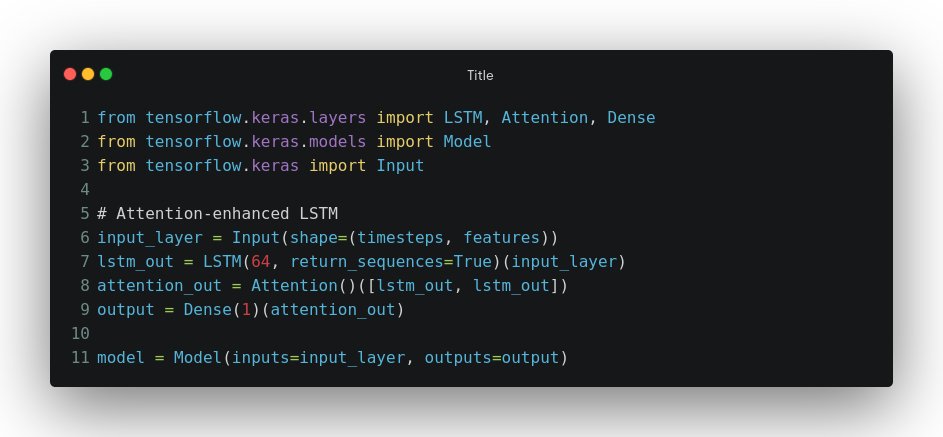
Architecture 5: Attention-based LSTM – Smart Focus Mechanism
The Approach
Attention mechanisms augment LSTM networks by learning to dynamically focus on the most relevant parts of input sequences. This selective attention proves especially valuable when dealing with irregular missing data patterns.
Implementation Strategy
Performance Leadership
Attention-based LSTMs achieve the highest accuracy improvements, with up to 10% enhancement in sequential retail demand forecasting, particularly during promotional periods with irregular sales patterns.
E-commerce Optimization
Major retail platforms implement attention-enhanced LSTMs to predict demand during flash sales and seasonal events, where traditional forecasting methods struggle with irregular purchasing behaviors.
Advanced Techniques: Combining LSTM Architectures for Incomplete Time Series
The most sophisticated forecasting systems often combine multiple approaches. Popular hybrid architectures include:
Attention + Bidirectional LSTM
This combination leverages both directional context and selective attention, proving particularly effective in complex sequential prediction tasks.
Masked + Autoencoder LSTM
Preprocessing with masking followed by autoencoder reconstruction provides robust handling of mixed missing data patterns.
Ensemble Approaches
Training multiple architectures and combining predictions through weighted averaging or stacking often yields superior results to individual models.
Implementation Best Practices for LSTM Incomplete Time Series Forecasting
Data Preprocessing
- Normalize sequences before training to improve convergence
- Validate missing data patterns to choose appropriate architecture
- Consider domain-specific imputation methods when preprocessing
Model Training
- Use appropriate loss functions for your forecasting objective
- Implement early stopping to prevent overfitting
- Monitor validation metrics specific to incomplete data scenarios
Hyperparameter Tuning
- Experiment with different LSTM units (32, 64, 128)
- Adjust sequence lengths based on missing data frequency
- Fine-tune attention parameters for attention-based models
Conclusion
Incomplete time series data presents significant challenges for traditional forecasting approaches, but specialized LSTM architectures provide robust solutions. Each of the five architectures—Masked, Bidirectional, Imputed, Autoencoder, and Attention-enhanced—offers unique advantages for different scenarios.
The key to success lies in matching your specific data characteristics and requirements with the appropriate architecture. For systems requiring maximum accuracy and having sufficient computational resources, Attention-based LSTMs provide the best performance. For simpler implementations with moderate missing data, Masked or Bidirectional LSTMs offer excellent alternatives.
As time series forecasting continues to evolve, hybrid approaches combining multiple architectures will likely become the gold standard for handling incomplete data in production systems.
Frequently Asked Questions
Q: What is the full form of LSTM?A: Long Short-Term Memory.
Q: Which LSTM architecture is best for large missing chunks? A: LSTM Autoencoder or Attention-based LSTM typically perform best for substantial data gaps, as they can learn to reconstruct missing patterns effectively.
Q: Can you combine these architectures? A: Absolutely. Hybrid approaches like Attention + Bidirectional LSTM are common and often provide superior performance compared to individual architectures.
Q: How do I choose between preprocessing imputation and architectural solutions? A: Consider your domain expertise, computational resources, and data characteristics. Preprocessing works well for regular patterns, while architectural solutions excel with complex, irregular missing data.
Q: What’s the computational overhead of these specialized architectures? A: Masked and Imputed LSTMs have minimal overhead, while Bidirectional models roughly double computation time. Autoencoders and Attention mechanisms require significantly more resources but provide proportional accuracy improvements.
Discover more from Neural Brain Works - The Tech blog
Subscribe to get the latest posts sent to your email.