
LSTM Architecture Explained: Components, Gates & Information Flow
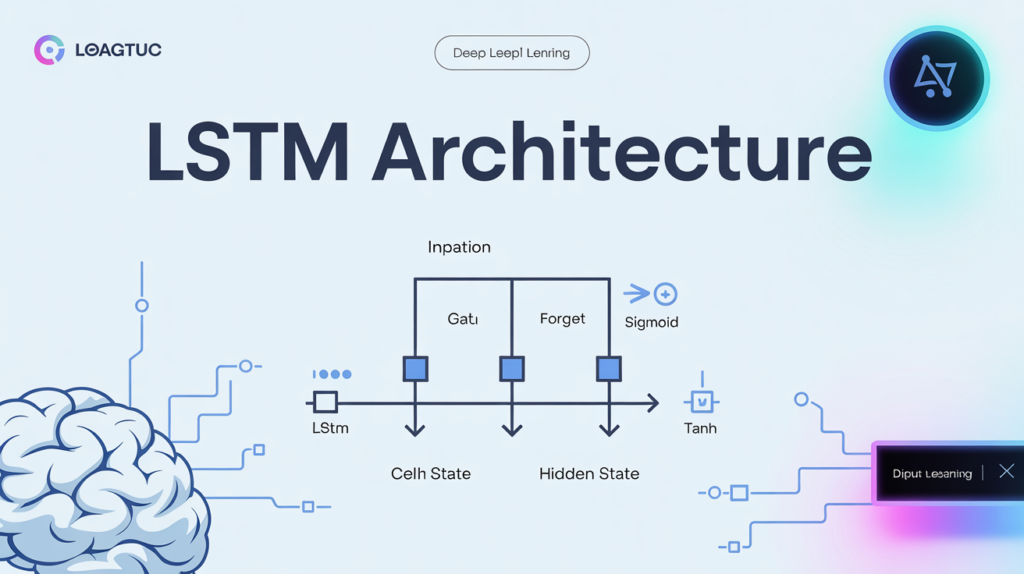
Long Short-Term Memory (LSTM) networks are a cornerstone of modern deep learning — especially when dealing with complex sequential data. But what really makes the LSTM architecture so effective? The answer lies in its unique internal structure and how it overcomes the limitations of vanilla RNNs.
Let’s explore how an LSTM cell is built, how its gates function, and how the information flows forward and backward through time.
🔍 What is LSTM Architecture?
At its core, LSTM architecture is an evolution of the simple RNN. In a simple RNN, information flows from one time step to the next through a hidden state. But standard RNNs suffer from the vanishing gradient problem, which makes it nearly impossible for them to learn long-range dependencies.
LSTM solves this with a cell state — a separate channel that acts like a long-term memory — and a system of learnable gates that control what to remember, what to forget, and what to output.
✅ Real-world example: In language translation, LSTMs can learn that a verb at the start of a sentence affects the correct translation at the end — something a vanilla RNN might easily forget.
🧩 Key Components of an LSTM Cell
When you look at an LSTM architecture diagram, you’ll always find these essential parts:
🔗 1. Cell State: The Conveyor Belt
The cell state is like a long conveyor belt that runs through the entire sequence. It carries the important information forward while only interacting with gates in a linear fashion. This minimal interaction means the gradient can flow backward easily during training, preventing it from vanishing.
✅ Fun fact: The cell state is what gives LSTM its “Long-Term” memory — something simple RNNs struggle to retain.
🔐 2. Hidden State: Short-Term Memory
The hidden state is what the LSTM outputs at each time step. It represents the “short-term memory” and works alongside the cell state to provide the necessary context for prediction.
This hidden state is also passed to the next LSTM cell, helping to build the entire sequence’s context step-by-step.
🚪 3. The Three Gates: LSTM’s Secret Weapon
The forget gate, input gate, and output gate are the true heart of the LSTM architecture.
- Forget Gate: Uses a sigmoid activation to decide which parts of the cell state to erase. Values close to 0 mean “forget this,” values close to 1 mean “keep this.”
- Input Gate: Also uses sigmoid to decide which new information to add. Works together with a tanh activation to create candidate values that can be added to the cell state.
- Output Gate: Controls what parts of the cell state to output as the hidden state for this time step.
These gates are fully trainable, so the model learns to dynamically adjust how much information it should remember or discard.
⚙️ 4. Element-Wise Operations
Inside each LSTM unit, there are element-wise multiplications and additions between the gates and the cell state. This design allows precise, fine-grained control over what information is allowed to flow through and what is blocked.
✅ Tip: When implementing LSTMs in frameworks like TensorFlow or Keras, you don’t need to manually define these operations — they’re built into the LSTM layer.
🔄 LSTM Forward Pass
In the forward pass, the LSTM processes a sequence step by step:
1️⃣ Receives input for the current time step plus the previous hidden state.
2️⃣ Computes the forget gate, input gate, and output gate values.
3️⃣ Updates the cell state based on the forget and input gates.
4️⃣ Produces the new hidden state using the output gate and the updated cell state.
✅ This process repeats for every time step in your input sequence — whether you’re generating text, predicting stock prices, or translating a sentence.
🔙 LSTM Backward Pass
During training, the backward pass (backpropagation through time, or BPTT) computes gradients for each gate and weight by flowing error signals backward through all time steps.
Unlike RNNs, where gradients tend to shrink to zero over long sequences, LSTM’s cell state allows constant error flow, maintaining gradient magnitude.
This makes LSTM architecture far more stable during training, especially for long sequences.
🔬 Cell State vs Hidden State
This is a common point of confusion. Here’s how they differ:
- Cell State (
c): Carries long-term memory across time steps. - Hidden State (
h): Short-term memory; output for the current step. - ✅ Both are updated at every step, but only the hidden state is exposed as output.
🧬 Activation Functions Inside LSTM
Each gate uses specific activations for a reason:
- Sigmoid: Acts like a soft switch. Its output range (0–1) makes it ideal for deciding “how much to let through.”
- Tanh: Keeps the cell state’s values between -1 and 1, adding non-linearity and stability.
Together, these activations make the LSTM both selective and smooth.
📈 LSTM in Real-World Architectures
✅ Time Series Forecasting
For predicting stock prices, sales, or weather patterns, LSTM’s architecture is ideal because it can remember seasonal trends and long-term influences.
✅ Language Models
LSTMs power many NLP tasks like language translation, sentiment analysis, and speech-to-text systems.
✅ Framework Implementations
Whether you’re using TensorFlow, Keras, or PyTorch, the LSTM layer abstracts away the cell architecture. But understanding the internals helps you fine-tune hyperparameters like sequence length, dropout, and recurrent dropout.
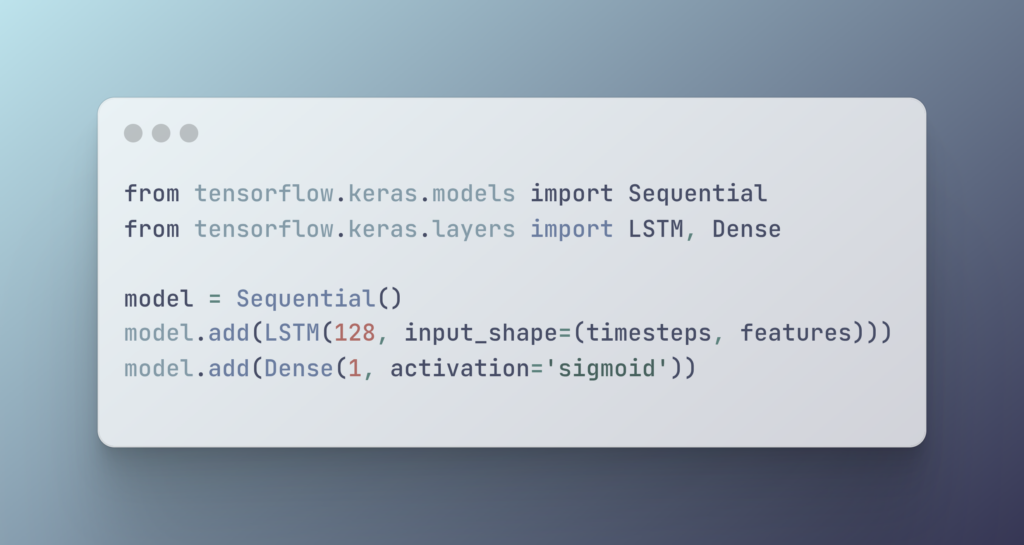
✅ Example:
🗂️ Advanced Variants
- Bidirectional LSTM: Processes input in both directions to capture future and past context.
- Stacked LSTM: Layers multiple LSTM cells on top of each other for deeper learning.
- Attention Mechanisms: Often combined with LSTMs to selectively focus on relevant parts of a sequence.
🌍 Useful Resources
- Visual explanation by Chris Olah: Understanding LSTMs
- Official TensorFlow guide: Recurrent Neural Networks
❓ FAQs About LSTM Architecture
1. What makes LSTM architecture unique?
Its gated cell design allows it to retain long-term memory, solving the vanishing gradient problem common in simple RNNs.
2. What is the difference between cell state and hidden state?
The cell state carries long-term memory, while the hidden state carries short-term output.
3. What role do activation functions play?
Sigmoid decides how much to keep or forget; tanh creates new candidate values in a stable range.
4. How is an LSTM forward pass different from backward pass?
The forward pass processes input; the backward pass updates weights by flowing gradients backward through time.
5. Can you stack multiple LSTM layers?
Yes! Stacked LSTMs increase learning capacity for complex tasks like machine translation.
Discover more from Neural Brain Works - The Tech blog
Subscribe to get the latest posts sent to your email.