
LSTM Forward Propagation: A Step-by-Step Guide with Equations
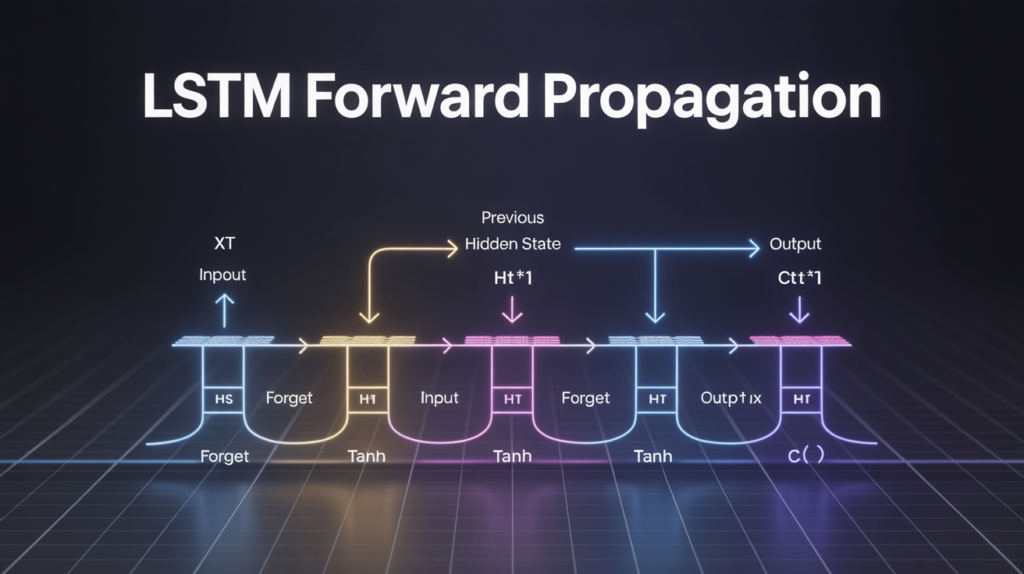
When working with sequential data like text, speech, or time series, Long Short-Term Memory (LSTM) networks are the gold standard — and at the heart of every LSTM is its forward propagation process. This is the step where the model takes input, updates its states, and makes predictions.
Unlike simple feed-forward networks, LSTMs pass information not just forward but through time, making their forward pass more involved but far more powerful.
In this guide, you’ll learn:
✅ What happens during LSTM forward propagation
✅ The role of gates, activations, and states
✅ Step-by-step equations (clean for screenshots)
✅ Matrix operations for batch processing
✅ Practical Python examples
✅ Debugging tips for real-world implementation
🔍 What is LSTM Forward Propagation?
In deep learning, forward propagation means computing the output of a model for a given input. For LSTMs, this means:
- Passing input through gates (forget, input, output)
- Updating the cell state (long-term memory)
- Producing the hidden state (short-term memory/output)
- Passing states forward to the next time step
✅ Why it matters: The forward pass sets up the backward pass (backpropagation through time). If you get this step wrong, gradients will be useless!
🗂️ Key Steps in LSTM Forward Propagation
The forward pass at time step t can be broken down into these sub-steps:
1️⃣ Combine Input & Previous Hidden State
2️⃣ Compute Forget Gate Activation
3️⃣ Compute Input Gate Activation & Candidate Values
4️⃣ Update the Cell State
5️⃣ Compute Output Gate Activation
6️⃣ Compute New Hidden State
Let’s expand each step!
🧩 Step 1: Combine Input & Previous Hidden State
At each time step, the LSTM takes:
- Current input vector xₜ
- Previous hidden state hₜ₋₁
These are concatenated to feed into the gates:
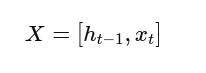
🚪 Step 2: Compute Forget Gate Activation
The forget gate decides which parts of the previous cell state Cₜ₋₁ to keep or forget.
Formula:

➕ Step 3: Compute Input Gate Activation & Candidate Values
This step updates the cell state with new info.
- Input gate: decides which parts of the candidate values to add.
- Candidate values: possible new information created with tanh.
Formulas:
Input gate:
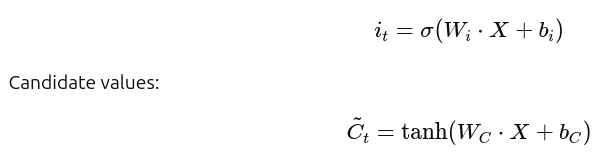
🔄 Step 4: Update the Cell State
Combine forget and input gate outputs to update the cell state:
Formula:

🔑 Step 5: Compute Output Gate Activation
The output gate controls what gets output as the hidden state.
Formula:
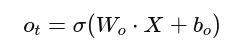
🧠 Step 6: Compute New Hidden State
The new hidden state is the output of the cell:
Formula:
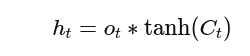
📊 How the LSTM Forward Pass Looks as a Computational Graph
The flow can be visualized like this:
Inputs:
xₜ, hₜ₋₁, Cₜ₋₁ → [Combine] → [Forget Gate] → [Input Gate + Candidate] → [Cell State Update] → [Output Gate] → [Hidden State]
✅ Tip: For big sequences, frameworks vectorize these operations for speed.
🧬 Activation Functions: Sigmoid & Tanh
- Sigmoid (σ): Good for gates since its output is [0, 1].
- Tanh: Keeps candidate values in [-1, 1] for numerical stability.
✅ Without these, gradients might explode or vanish.
⚙️ Practical Matrix Operations
In real implementations:
- Inputs are batched: shape
[batch_size, input_size] - Hidden & cell states are vectors per batch.
- Gates are matrix multiplications:
X @ W + bfor each gate.
✅ Trick: Using combined weight matrices reduces redundant operations.
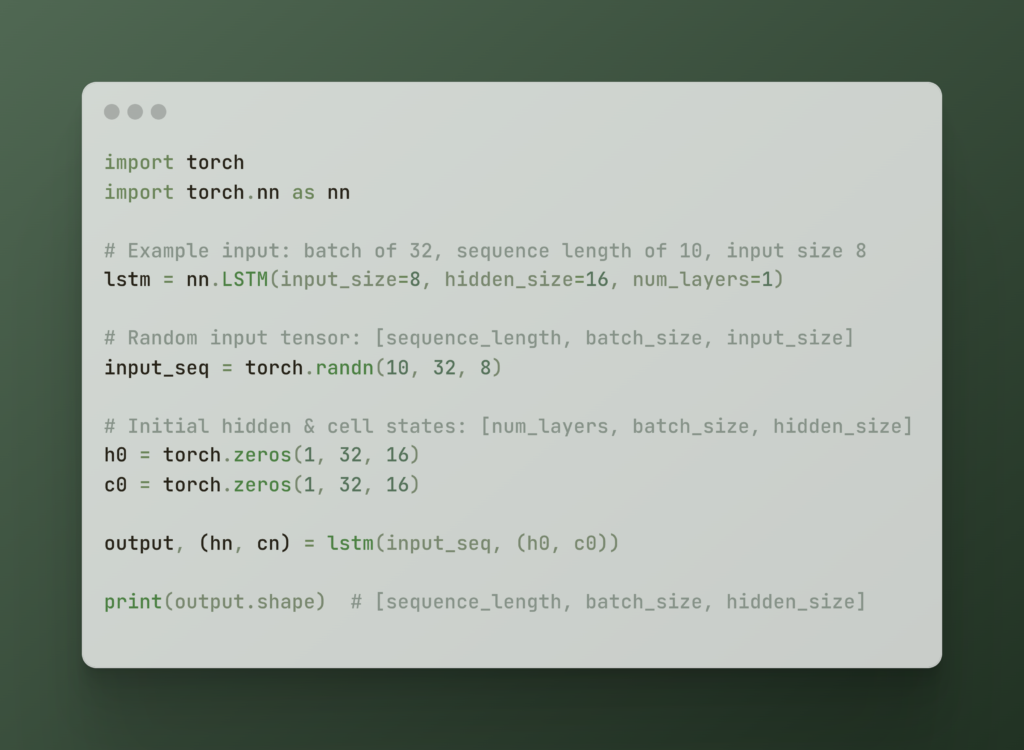
🖥️ Example: LSTM Forward Pass in Python (PyTorch)
🔬 Numerical Stability & Debugging Tips
✔️ Gradient Checking: Verify that gradients flow backward properly after the forward pass.
✔️ Saturating Activations: Watch for gates stuck at 0 or 1 — this means learning is not dynamic.
✔️ Batch Processing: Use vectorization for faster computation on GPUs.
📈 Performance Optimization
✅ Matrix Fusion: Combine gate weight matrices into one large matrix for faster operations.
✅ Vectorization: Use batch operations to handle multiple sequences simultaneously.
✅ Clip Gradients: Helps control exploding gradients during training.
🌍 Useful Resources
- Chris Olah: Understanding LSTMs
- PyTorch Docs: RNN, LSTM, GRU
❓ FAQs About LSTM Forward Propagation
1. Why is forward propagation important?
It’s the step where your model generates outputs — errors here ruin your backward pass.
2. Do I need to implement the equations manually?
No. Libraries like TensorFlow and PyTorch do it for you. But knowing the math helps you debug.
3. How can I verify my forward pass?
Print shapes, values, and check that activations are not saturating.
4. Why do we concatenate input and hidden state?
This lets the gates use both the current input and previous context.
5. What happens if the output gate fails?
Your model’s predictions will be poor, because the hidden state carries incorrect info forward.
Discover more from Neural Brain Works - The Tech blog
Subscribe to get the latest posts sent to your email.