
LSTM Gates Explained: How the Forget, Input & Output Gates Work
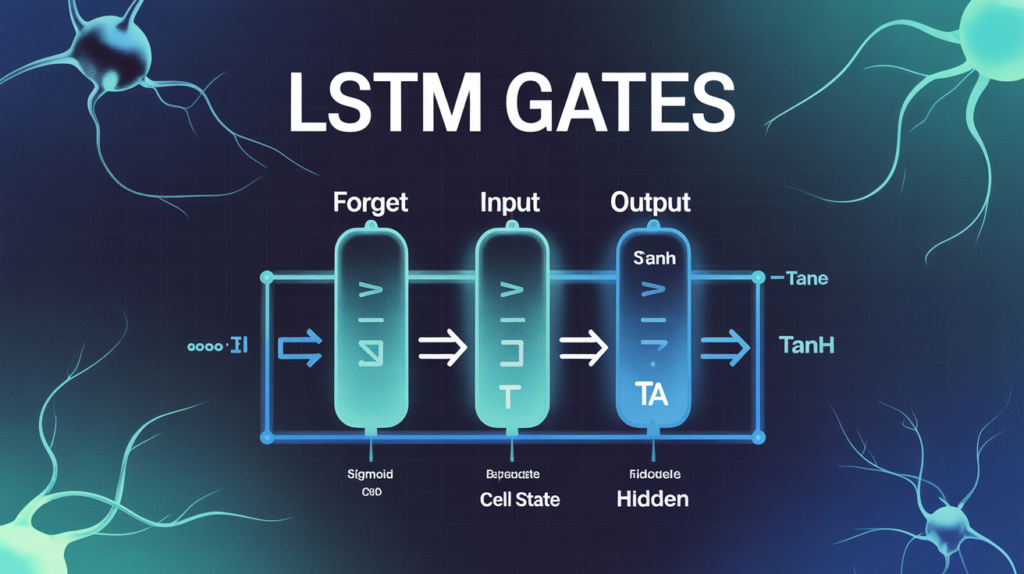
When it comes to making LSTM networks robust, stable, and capable of remembering information across long sequences, the real stars are the gates. Think of these gates as tiny decision units that constantly ask: “Should I remember this? Should I forget this? Should I output this?”
Unlike simple RNNs — which easily forget what happened far back in a sequence — LSTM gates keep the model’s memory organized and relevant, solving the vanishing gradient problem.
In this guide, you’ll understand:
- What each LSTM gate does
- How the gates use activations like sigmoid and tanh
- The step-by-step flow of information
- Practical examples for how each gate works in real tasks
🔍 What Are LSTM Gates?
Each LSTM cell has three gates plus a cell state and hidden state. The gates are neural network layers that learn to filter and control information dynamically. This design allows the network to remember long-term dependencies without gradients shrinking to zero.
✅ Practical context:
In tasks like speech recognition, LSTM gates help the model remember the first few syllables to predict the next ones accurately — even when words are far apart.
🗂️ The Three Core LSTM Gates
Let’s break them down with clear explanations and readable formulas.
🚪 1. Forget Gate: Decide What to Discard
The forget gate checks the cell state and decides what to keep and what to erase. Its output is always between 0 and 1, thanks to the sigmoid function.
Key points:
- If the forget gate outputs 1, the information is kept.
- If it outputs 0, the information is forgotten.
- Intermediate values allow for partial forgetting.
✅ Example: In language models, it forgets old context when a new sentence starts.
Forget Gate Formula:

2. Input Gate: Decide What to Add
The input gate decides what new information should be added to the cell state. It works with:
- A sigmoid gate layer to decide which values to update
- A tanh layer to create candidate values
✅ Example: In stock prediction, the input gate stores new trends in the data stream.
Readable Input Gate Formulas:
Sigmoid part:
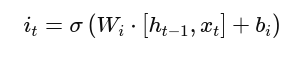
Candidate value:
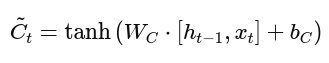

3. Output Gate: Decide What to Output
The output gate filters what parts of the cell state should be output as the hidden state. This hidden state is what gets passed to the next time step and used for predictions.
✅ Example: For language generation, the output gate decides which words to produce next.
Readable Output Gate Formulas:
Output gate:

🧬 How the Gates Interact
Here’s how all three gates work together for each time step:
1️⃣ Forget: Remove irrelevant parts from old memory.
2️⃣ Input: Add new relevant information.
3️⃣ Output: Decide what to share as output.
This selective memory management is the secret behind LSTM’s ability to model long-term dependencies, which is impossible for vanilla RNNs.
✅ Tip: In Keras or TensorFlow, you don’t have to code the gates manually — they’re built into the LSTM layer.
⚙️ Sigmoid vs Tanh Activations
- Sigmoid activation (σ\sigmaσ) works perfectly for gates: its 0–1 range is ideal for “soft switches”.
- Tanh activation (tanh\tanhtanh) creates new candidate values, keeping them within -1 and 1 to maintain stability.
✅ Fun insight: Without these activations, the gates could push cell state values to explode or shrink, making training unstable.
🔍 Cell State vs Hidden State
Cell State (C_t):
- The conveyor belt of memory.
- Carries long-term information with minimal modifications.
Hidden State (h_t):
- Short-term working memory.
- Used for predictions and as input to the next cell.
✅ Together, they make LSTM robust to long sequences!
🔬 More Gate Mechanism Details
✔️ Candidate Value Generation: The input gate’s tanh function generates new possible additions to memory.
✔️ Information Filtering: The forget gate acts like a noise-cancelling filter.
✔️ Selective Attention: Gates allow the LSTM to focus on what matters for the task at hand.
✔️ Training Stability: Proper gate tuning prevents gradient issues.
🧠 Practical Applications of LSTM Gates
✅ Language Translation: Keep context from the start of a sentence until the end.
✅ Speech Recognition: Retain sounds or words until the full word is clear.
✅ Time Series Forecasting: Remember trends or seasonal patterns.
🧩 Gate Mechanism Tuning Tips
✅ Use Dropout: Prevent overfitting by adding dropout between gates.
✅ Gradient Clipping: Stop exploding gradients when backpropagating through time.
✅ Visualize Activations: Tools like TensorBoard help you see if gates are saturating (always 0 or 1).
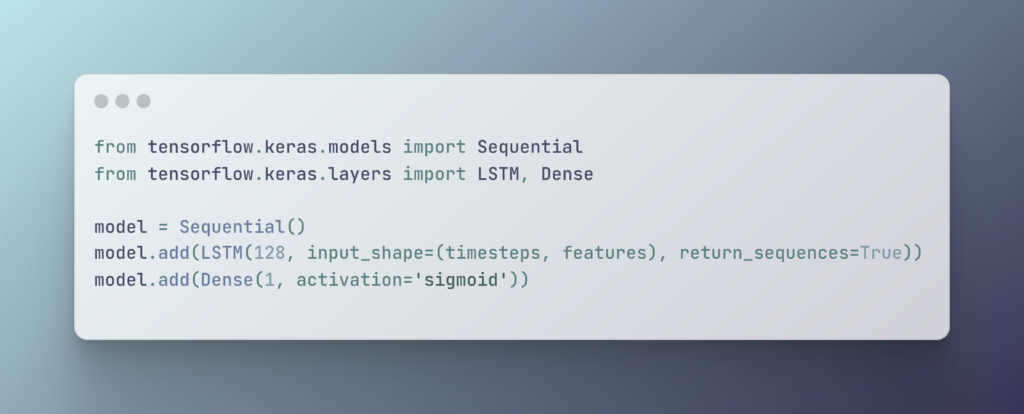
📊 Example Code Snippet (Keras)
🌍 Useful Links
- Chris Olah’s Understanding LSTMs
- TensorFlow’s Guide to RNNs
❓ FAQs About LSTM Gates
1. What is the main role of LSTM gates?
They control what information the cell keeps, forgets, or outputs, enabling long-term memory.
2. Why does each gate use sigmoid or tanh?
Sigmoid acts like a gate switch; tanh adds non-linear variation without large value jumps.
3. What happens if gates aren’t working well?
The network may forget useful information too soon or keep irrelevant data, harming accuracy.
4. Can gates be visualized?
Yes! Researchers often plot gate activations to ensure they’re learning dynamic switching.
5. Do you have to define gates manually?
No — popular frameworks like TensorFlow and PyTorch handle gates inside the LSTM layer.
Discover more from Neural Brain Works - The Tech blog
Subscribe to get the latest posts sent to your email.