
Vanishing Gradient Problem Explained: Why RNNs Struggle With Long-Term Memory
One of the biggest obstacles in training deep neural networks — especially Recurrent Neural Networks (RNNs) — is the vanishing gradient problem. This issue silently sabotages learning by shrinking gradients during backpropagation, making it impossible for a model to learn from long sequences.
In this technical guide, we’ll break down what the vanishing gradient problem is, how it affects RNNs, how LSTMs solve it, and what techniques (like gradient clipping) help mitigate it.
🔍 What is the Vanishing Gradient Problem?
The vanishing gradient problem occurs during backpropagation when the gradients of loss with respect to earlier layers become very small — often approaching zero. As a result, these layers stop learning effectively.
This is especially problematic in deep networks and sequential models, where information must pass through many time steps or layers.
🔢 Mathematical View:
When applying the chain rule in backpropagation through time (BPTT), you multiply many small derivatives together. If these derivatives are < 1, the final product shrinks exponentially.
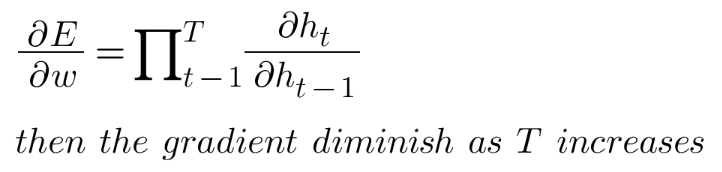
🔁 Why RNNs Suffer from Vanishing Gradients
RNNs process sequences by recursively updating a hidden state. During training, the model adjusts weights through backpropagation through time (BPTT). But when the sequence is long, and activation functions like sigmoid or tanh are used, gradients either vanish or explode.
Key reasons:
- Repeated multiplications of small gradients.
- Saturating activation functions (like tanh/sigmoid).
- Long-term dependency chains where early inputs influence late outputs.
As a result, the model can’t learn from earlier steps in a sequence — critical for tasks like language modeling, time series, or video analysis.
⚠️ Vanishing vs Exploding Gradients
While vanishing gradients make learning impossible due to values shrinking toward zero, exploding gradients do the opposite — values grow uncontrollably large, leading to training instability or NaN errors.
Both problems are symptoms of unstable gradient flow.
💥 How LSTMs Solve the Vanishing Gradient Problem
The invention of Long Short-Term Memory (LSTM) networks was a breakthrough. LSTMs were specifically designed to address the vanishing gradient problem.
Key mechanisms:
- Memory Cell: Stores long-term information with minimal updates unless necessary.
- Gating System: Controls how information is added, forgotten, or passed forward.
- Forget Gate
- Input Gate
- Output Gate
This architecture allows constant error flow through time, enabling LSTMs to retain gradients and learn from long-term dependencies — something RNNs fail at.
🧰 Techniques to Prevent Vanishing Gradient Problem
Even without switching to LSTMs or GRUs, there are several engineering solutions to reduce the impact of vanishing gradients:
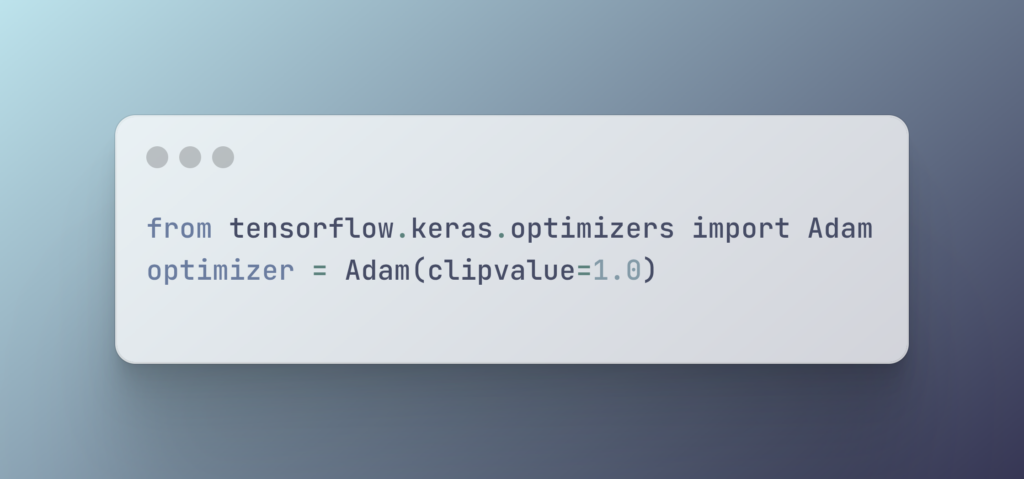
🔧 1. Gradient Clipping
Limits the maximum value of gradients during training. Prevents both exploding and vanishing behavior by constraining updates.
🔧 2. Use of ReLU or Leaky ReLU
ReLU avoids the saturation problem of sigmoid/tanh. However, it’s not often used in standard RNNs due to instability but works well in feedforward architectures.
🔧 3. Proper Weight Initialization
Using techniques like Xavier (Glorot) or He initialization helps maintain gradient magnitudes during training.
🔧 4. Layer Normalization
Stabilizes activations and improves gradient flow.
🔧 5. Shorter Sequences
In some applications, breaking long sequences into shorter chunks can reduce gradient degradation.
🧬 Activation Functions & Saturation
The choice of activation function plays a major role. For example:
- Sigmoid squashes outputs to 0–1, often leading to very small gradients.
- Tanh maps between -1 and 1, but still suffers from saturation.
- ReLU avoids saturation for positive inputs but introduces “dead neurons” for negatives.
🧠 Example: Vanishing Gradients in Action
Let’s simulate an RNN trying to learn a simple long-range dependency (like copying a token 100 steps ago). A vanilla RNN will fail to learn this after many epochs. Meanwhile, an LSTM model will succeed, even with fewer epochs.
This shows how badly vanishing gradient problem in RNNs can cripple learning from distant context.
🧪 LSTM Gradient Flow vs RNN
In visualizations of gradient flow, LSTMs show smoother, more sustained gradients across time steps. RNNs, in contrast, show almost no gradient flow in earlier layers — which confirms the mathematical cause.
📈 Other Gradient-Based Issues
Along with vanishing gradients, you may encounter:
- Exploding gradients → use gradient clipping
- Numerical instability → caused by very small or large weights
- Learning rate sensitivity → too high causes divergence; too low slows learning
🌍 Useful Resources
- Read Chris Olah’s visual guide to LSTMs: Understanding LSTMs
- Deep dive into gradient flow in this Stanford CS231n Lecture Notes
- Explore Exploding and Vanishing Gradient Explained
❓ FAQs About Vanishing Gradient Problem
1. What is the vanishing gradient problem?
It’s a challenge during backpropagation where gradients become too small to update early layers, halting learning.
2. Why does it affect RNNs more?
Because RNNs unfold across many time steps, gradients shrink with each step, making it hard to learn long-term dependencies.
3. How does LSTM fix the vanishing gradient problem?
LSTMs use a memory cell and gates that let error signals flow backward across time without vanishing.
4. What’s the difference between vanishing and exploding gradients?
Vanishing gradients shrink toward zero; exploding gradients grow uncontrollably, both causing learning issues.
5. How can I fix it in my model?
Use LSTM or GRU, try gradient clipping, layer normalization, better weight initialization, or shorter sequences.
Discover more from Neural Brain Works - The Tech blog
Subscribe to get the latest posts sent to your email.